为了使用AI,让大部分人学着写Prompt,然后被快速迭代
同样很多人拿到AI结果超出预期,然后对一款AI应用一个模型就赞叹不已
但反过来说,超出预期不也是没有击中你的意图嘛?
那它的意图揣测,还是否合格呢?文章内,没有答案,只是我的实验思索,做个垂类场景下的意图拆解。而且这只是中间态,等待明年这时候,独立AI就可能覆盖这些信息(甚至现在的LLM已经如此处理了)
文章很碎,想到哪儿写到哪儿。虽然设计结构可套用在很多当场景,但本文只停留在意图揣测,
这几个月,无论是在公司项目,还自己实验性研究项目。面向消费场景下的AI,意图揣测是绕不过去的坎。
我线上线下收集数据,试图将意图定义的更准确,利用RAG来协助矫正。但结果就是RAG越来难以维护,某一场景下的意图越来越泛泛。
用户输入一定包含了多层意图,而不是纸面信息。从浅层意图的“直接动作”,到中层意图的“任务目标”,最后深层意图的“隐性动机”,AI往往在任务目标的理解时已经失真。
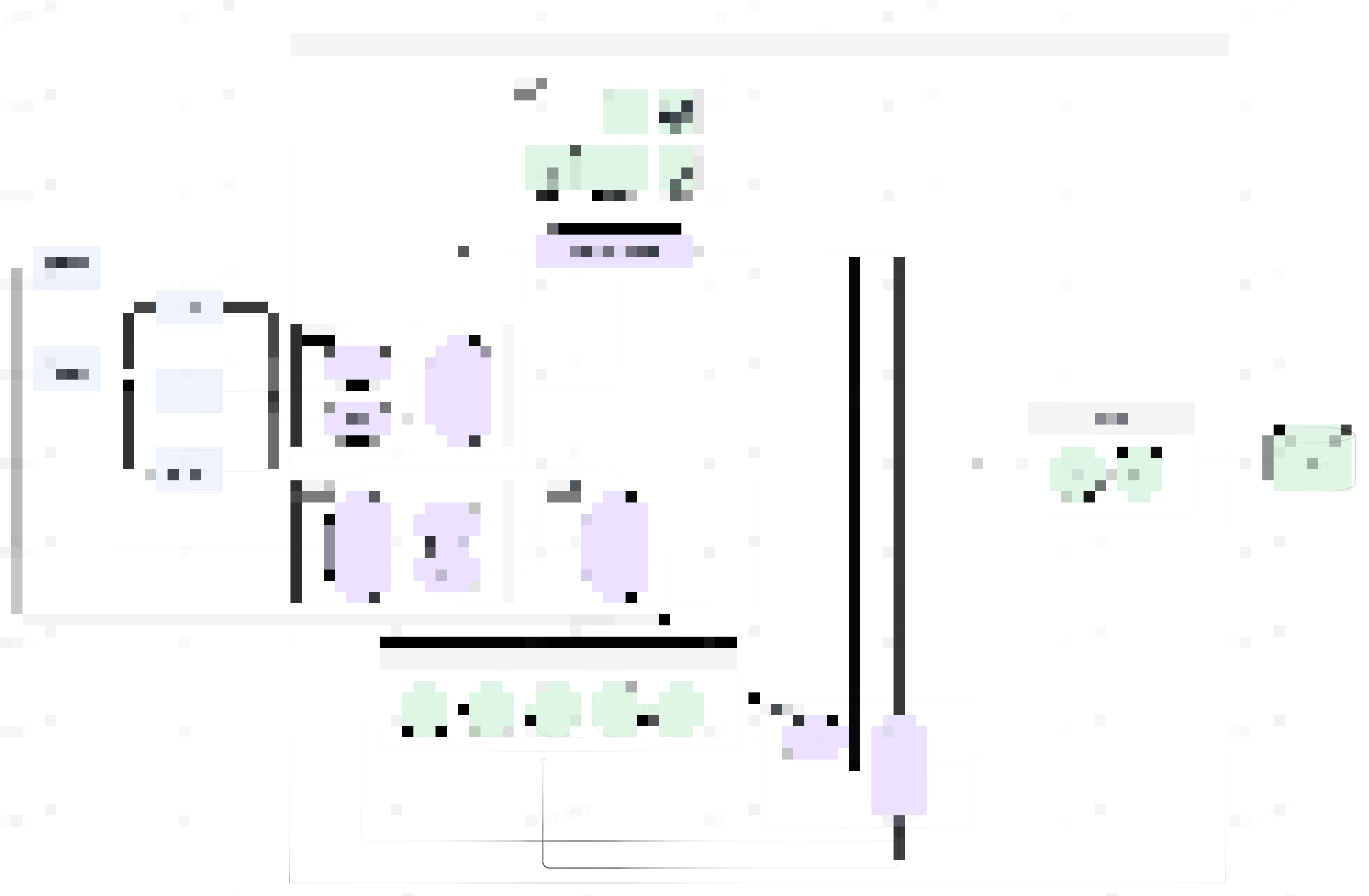
在一个黑盒AI上,所有做过Agent工程的同学,都会拆解到下面几个层级:
Raw Input ➡️ Abstraction Layer ➡️ Modeling Layer ➡️ Output Layer
我精炼了一下每个层级风险
Abstraction Layer:有忽略上下文的风险
Modeling Layer:存在过度简化细节风险
Output Layer:存在收敛失真风险
AI的 节点碎片化与结构化
这有点像在写游戏角色控制器,如同状态机,设计合理debug轻松,设计不合理,一样黏连成网就像是走迷宫
基于上面三个层级这么几个设计思维:
- 保持每个节点只有一到两个信息片输入,关键节点则最多三个输入
- 每个层级之间的节点相互独立,互不干扰
- 每个节点用于处理信息片的System Prompt干练简洁描述,定义简洁输出
- 每层串联节点之间,做好合理的动态权重(若有必要则需要做几个条件平均节点,做信息收敛)
- 最后输出层,一定要加入扰动节点(看业务状态,目标是增加输出的鲁棒性,给用户一定的二次编辑权)
- 建立独立于流程中的过载信息收集节点,一般在输出前做校验,用于打动态信息补丁或者重跑Modeling layer层的节点做信息建模
- 建立额外一条全AI自主的workflow(非人工接入,时情况兜底)
- 节点信息不回流,节点只跑一次,节点不人为设定“身份”,节点只做“螺丝左拧15度”的任务
穷举与建模
缺少数据,RAG索引不完善,在垂类场景下时最合适的应用
第一部分的核心思想为:
咬文嚼字
咬文嚼字,故名思义,每个节点只读上下文中的一个信息片,做好“模糊 ➡️ 结构化的转译”。所以需要一个独立Agent做字词图上下文任务的穷举拆分,同时通过构造函数创建几个接受独立信息片的Agent。
由于这部分的节点创建输入输出都是名词未知的,所以我称这些节点为无量纲节点。而且每次任务都会节点销毁,再创建。
这些节点目的是,解析单个词在上下文和有限语境中的可能穷举
第二部分的核心思想:
多层次意图建模
意图是分层的:
1. 显性意图- 关键词
2. 隐性意图- 用户历史偏好/上下问词缀联动
3. 深层意图:情绪/表达目标(孤独、力量、童趣、深邃)
该层级下,最基础需要建立3三个节点(如果上级节点超过9个(一般来说也就3~5个),则需动态扩建,否则AI内部失真严重),分别承接处理,输出结果为硬信号、软信号、弱信号:
Hard Signals ➡️ 必须满足
Soft Signals ➡️ 可以参考
Weak Signals ➡️ 尝试性灵感
最后就是条件加权的节点介入,做到硬信号要锁死,软信号可平衡,弱信号保持弹性
第三部分的核心思想:
验证偏差
这块就会依赖过载信息节点的输出,与最终output做偏离矫正。
用户输入的信息越少,而信息离散较为集中,则说明用户没有非常深度的信息,可以直接输出
用户输入的信息越大,信息离散过多,则需要执行多条输出,甚至重新做硬/软/弱信号的解析
至于偏差值则由业务而定,创作类的可以较大,效能类的则需要收窄。
有人会吐槽:这token不是很浪费嘛?
但是实际上精炼的输入输出和长篇输入输出差距不大,缺点就是和三方服务的交互时长。导致工程中常常多个任务并排跑
写在最后——输出常见坑点
- 过度揣测,AI替用户做主,生成了“地狱风火焰怪物”,而用户只是想要一个“温柔火焰小精灵”。
扰动节点,避免锁死单一解读。
-
模糊与执行性的冲突,创作者的模糊表述有价值,但AI需要结构化结果。
这个很难解决,如同“意境”与“描述”,也是最大卡点
-
偏好漂移,过度依赖历史偏好会误导结果。
这个问题虽然没在实验中出现过,但仍需引入短期/长期权重,允许偏好切换。
-
黑箱感,AI揣测的结果用户“不知道为什么是这样”
也就是所谓的抽奖,LLM的thinking模式会把思考过程告知给用户,纯文字过程也可以这样去做预期管理。
-
模型幻觉/乱加戏,AI可能胡乱补充,在扰动中常见问题
保持可解释性,并让用户快速修正。
这个是真·商业实战的意图揣测设计落地,超级厚码保护!